OSINT for non nerds
Created on Thu 22 May 2023

I would like to preface this blog post with a quick foreword. I usually write technical work inside of this blog and the objective of this current post is to be as non technical as possible. I always try to branch out and meet personally people in different fields that are not technical related like mine. After discussing with non-nerds for a bit I discovered that not a lot of people know about OSINT and online investigation in general. I thought that this is quite a useful skill to showcase since the process is simple to grasp and is always quite nice in a pinch if you need data for a specific topic or just interested in finding information about a person or a company. To be able to follow along you will only need a web-browser since I am keeping this as beginner friendly as possible.
I am going to structure this post as a mini course to give people an overall idea of what OSINT is what you can do with it and how it can help you in your day to day life. At the end of this post we will string everything together by completing a little challenge with my guidance on a cybersecurity website called tryhackme. The intended way to complete that specific exercise is to use technical tools since it is a platform to learn cyber security but for the purpose of this specific post I want to take an approach where you do not need to know technical things like linux, the terminal. If you are looking for a post about that kind of stuff I would recommend to go through my other posts.
WTF is OSINT?
OSINT or also Open Source INvesTigation, is basically the art of using Open Source or also put public knowledge information to carry out investigation. When you are stalking one of your strange exes on facebook that is basically OSINT the only difference is that when someone does it with real OSINT experience they find a lot more creepy stuff than just pictures of there exes new partner.
Now like every thing cyber security related the process of getting to your desired goal is overall the same. We first need to determine something us nerds called the scope. Usually in OSINT that is what information do we have to start with and how far we can go. The main crutch with OSINT and when you can do it well it can get scary and intrusive fast. Let's give a small example: We target a person that we want to find information on and slowly but surely we gather more and more information about them then we discover there passwords on a leaked database and then we have full access to their email address. That would not be good if we don't have their specific consent. So just a quick note always be a bit careful on what you are looking for.
How do I OSINT?

Scoping
Now like previously said you need to understand what you are targeting mostly this will come with experience because at first it's hard to understand where do I start where do I go but the more you practice the better you will get at this specific section. I usually keep in mind a few questions I ask myself to start off. What am I targeting? What is off-limits? What information am I trying to get? How long am I willing to spend on this? What information will be enough? Now those questions might not apply for every engagements but most of the time they are quite helpful for me to have an overall idea of what I am trying to do.
Reconnaissance
Now this is the first actual step where we get our hands dirty so in this step I usually do 70% of the work since it is where you are doing all of the actual research on your target getting information and looking up as much data as possible.
Going through the data found
Now after gathering data about your target what do you do with it? Well it's quite simple you go through all of it to find more stuff to research. Basically if you find for example email addresses and saved them in your database (I use this word very lightly Imagine just a notepad where you save all your information) you would then take those emails and use them to find more information by seeing where those emails appear online. I spend at least 30% of my time on this bit since I got quite good after a few years of practice to go through tons of data.
Report writing
Now this bit is basically more for the professional side of the job this is where you take all of the sensitive data you found and put them together inside of the report to showcase the client his overall fingerprint online.
Now I will dive into the reconnaissance part which will be the focus inside of this post since this is where most of the techniques are located. The scoping and data analysis is where experience speaks the most so I can only recommend to just get as much practice in to get better at it :).
Where to start?
The first specific technique which will cover most of the other ones and I think is a staple of OSINT is something called Google Dorking/Google Dorks. Basically when you want to understand something you start with google and research on google. Google dorks are the advanced version of looking stuff up like How to use a washing machine. But instead you would be using google advanced features to get the information you would want.
Google Dorks

The name for this is quite deceptive even if it has google inside of the name. Google Dorking is not specific to the google search engine. Most search engines have advanced commands to be used to that you can extract as much information as possible from the searches. A few examples for google specifically are the following:
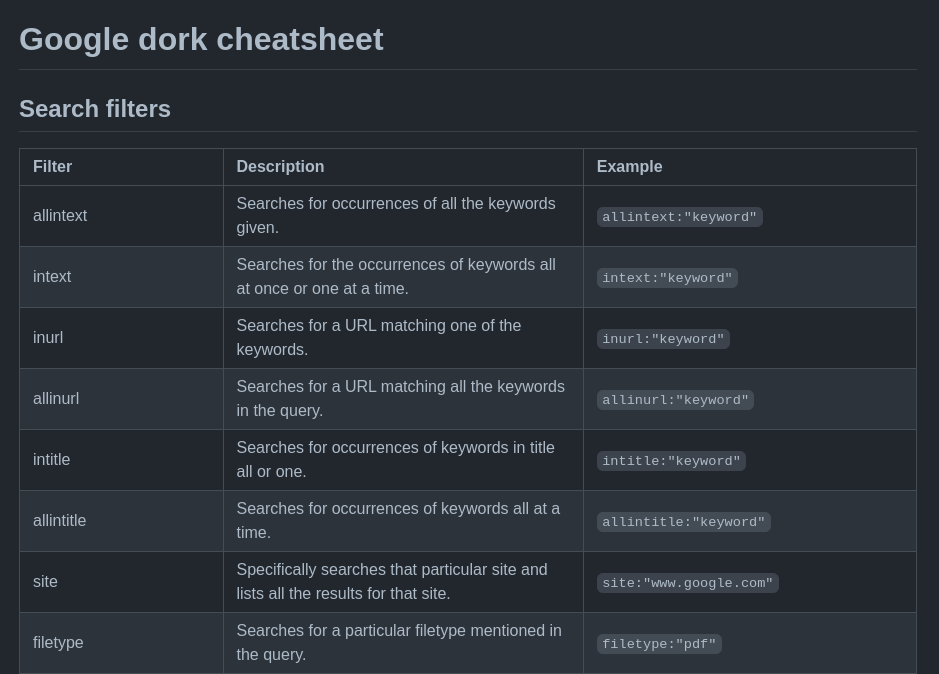
Using those special operators you can do advanced searches on google. Like find every pdf found on a website:
site:leosmith.wtf filetype:pdf
I recommend to try that specific dork for you to get a feel for it. The leosmith.wtf section can be changed to any website wanted. For that one specifically you can see that it returns all of the pdfs that are linked on my website.
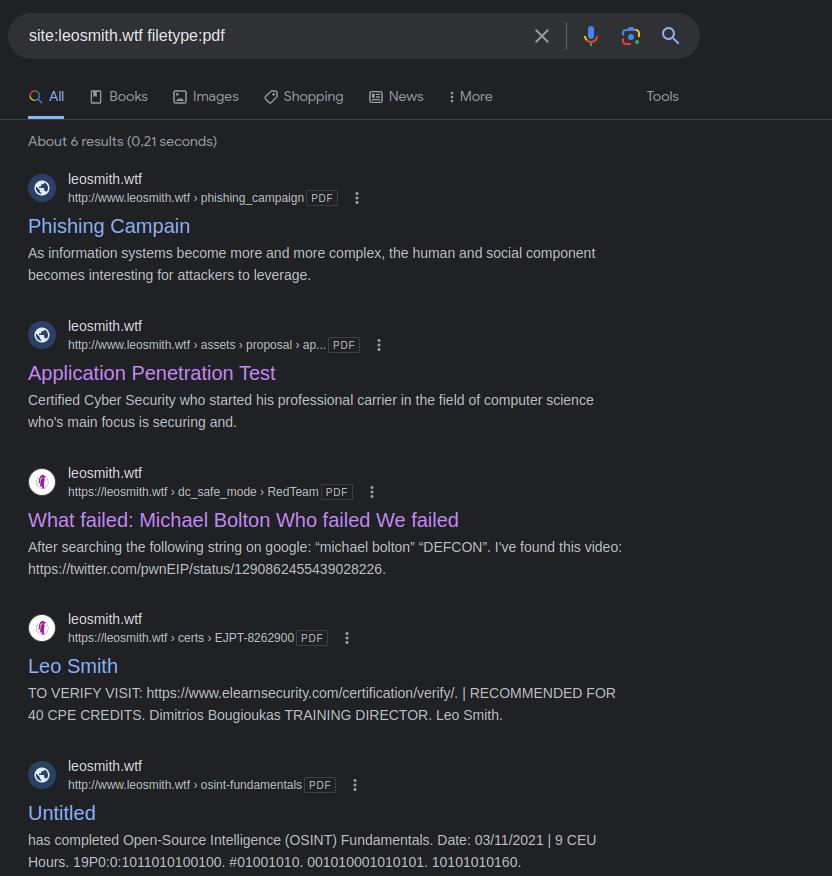
Now to build upon the knowledge of finding pdf files we can push this a bit further by trying to find a piece of text inside of every file on a website. Let's imagine that I was not very diligent on what I upload on my website and I have a pdf with a sensitive word like password inside of one of my pdfs and it has a admin password. We could change the search to something like this:
site:leosmith.wtf filetype:pdf intext:password
Now the new command here is intext. This will tell google please look for every occurrence of that word inside of all the pdfs from leosmith.wtf.
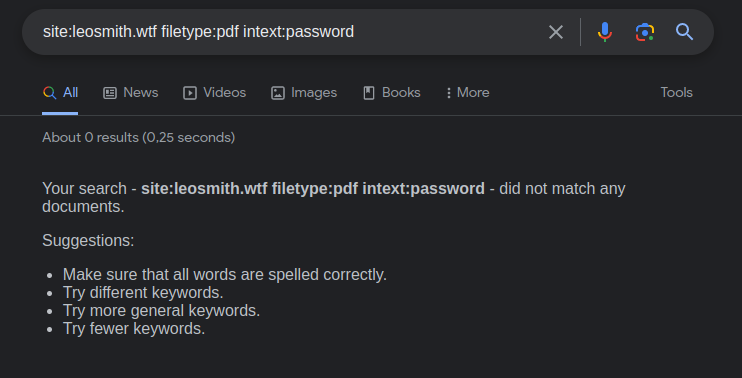
In this specific case not surprisingly there is no results because I do care a lot about what I upload on my website. I do invite you to try out on my website more google dorks and if anything interesting is found you could contact me on linked in and I would edit the post to feature you inside of it with a little section where I would showcase your finding.
Now in this example I did focus a lot on the google search engine since it will most likely be the one most people are familiar with. But me personally I use multiple engines to find different information and most of the ones I use have their own equivalent of advanced search fields. duckduckgo advanced search syntax
Wayback Machine
Now an other thing to think about is also time. It sounds a bit random but a lot of time people will disclose something online realise they are oversharing and then delete it. Sometimes if it is a big site there will be an archive of it a cute example to start with is the wayback machine this is a website that archives websites a bit like an online museum. You can use this website to view how websites where back in the day:
The wayback machine is not the only way to get older versions of website using googles own cache of websites can be proved very effective as well. If you have a url of a website that doesn't exist anymore you can still might view it inside of googles cache. For example my old domain .xyz is not online anymore but google still has it cached and you can still view old blog posts from it:
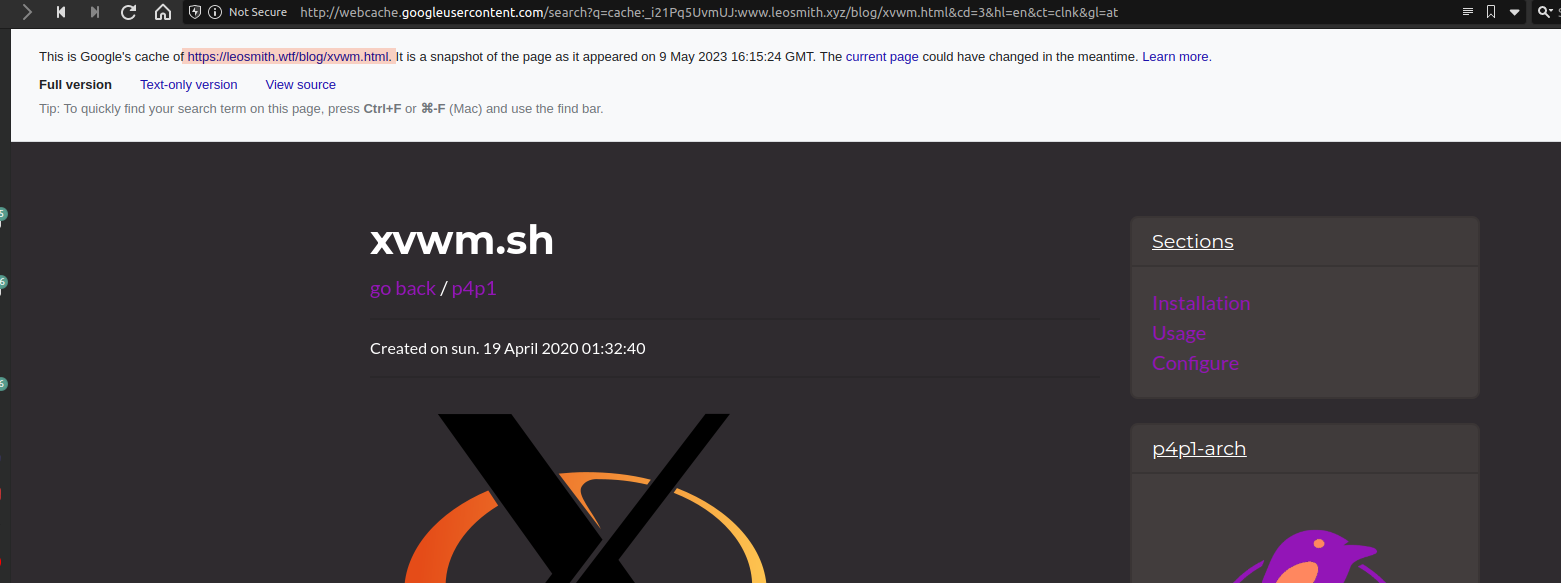
Now in this specific example the google cache does know that it is not .wtf instead of .xyz so it will be redirecting you to that specific cache. To view google cache it is quite easy inside of a search item in google you have three little dots next to the search query:

When selecting those dots you will see a little pop-up where you can access the cache:
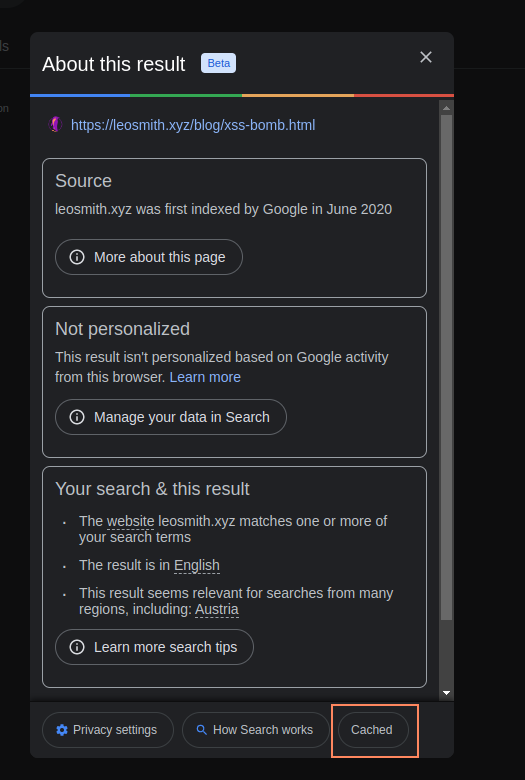
To simplify this process here I personally use a extension on chrome called go back in time. It has been removed from the chrome store for violating the extension guidelines but it literally allows me to right click on any website and get archive information in two clicks. more info here
Reverse Image search
Another important finding is images. From images a lot of information can be disclosed like a location, people etc... I will go through the first and most simple technique is reverse image searching now with google and other search engines you can take an image and try to find other places on the web where a specific image or similar appeared. This is quite useful for detecting scam accounts. Some use images from not very famous "celebrities" and the real identity of the picture can be found quite fast through this technique.

Usually the best for reverse image searching is using the search engine yandex. I personally use a combination of all of them using site like the following: https://www.reverseimagesearch.com
Same as the wayback machine there is extensions available to simplify this process like reveye. Also there are services available that uses facial recognition technology to do reverse image searches like PimEyes.
Metadata
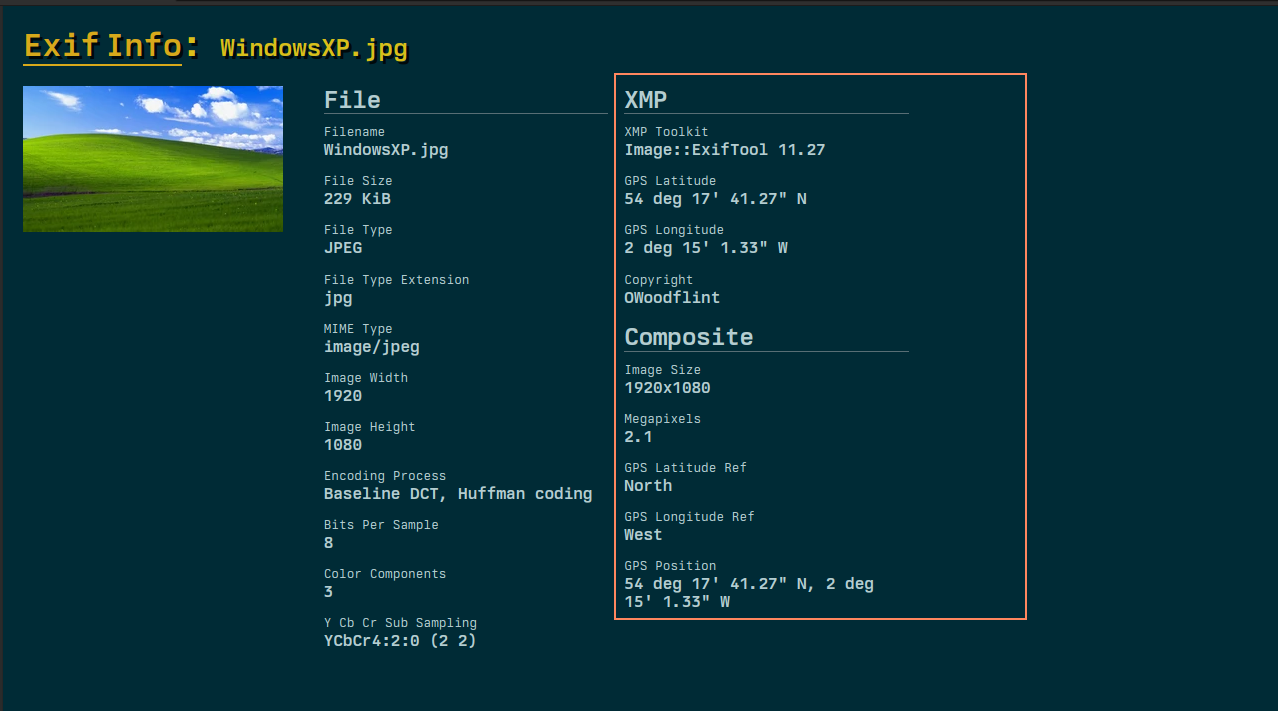
Metadata can be many things but usually it is considered to be data that describes other data. In out case for OSINT we might want to see if certain files/images have data about the author or where the file was created. This for example is quite common with photos. Some websites now have been good at removing metadata from photos but sometimes this step is overlooked so if a photo is found without being to descriptive we can use tools to view this "hidden" data that would give more information about the file. Inside of photos specifically there is something call exif data. Based on a protocol to allow files to have extra information this data can be extracted from files. A good website to view this kind of information is exifinfo.org.
Social Media
For the last section these techniques do change really often so aren't easily explained but going through the main social media accounts of the entities you are trying to target is a bit of a no brain-er a lot of people tend to overshare on social media and a lot of information can be found on such websites to help gather intelligence. For me my favourite is linked-in to then find employees and then look online if any passwords from their personal account got dumped and then to use those passwords on their professional email addresses. Since most people reuse passwords this technique is quite effective. There are some services available to look-up on multiple sites at once if a username is existent or not:

Namechk is a famous one.
Practice
In this section I recommend following along to give you some guided practice on the process. We will be completing the following challenge.
To start we are given a image file. Like explained above we will use the exiftool to see what information we can get:
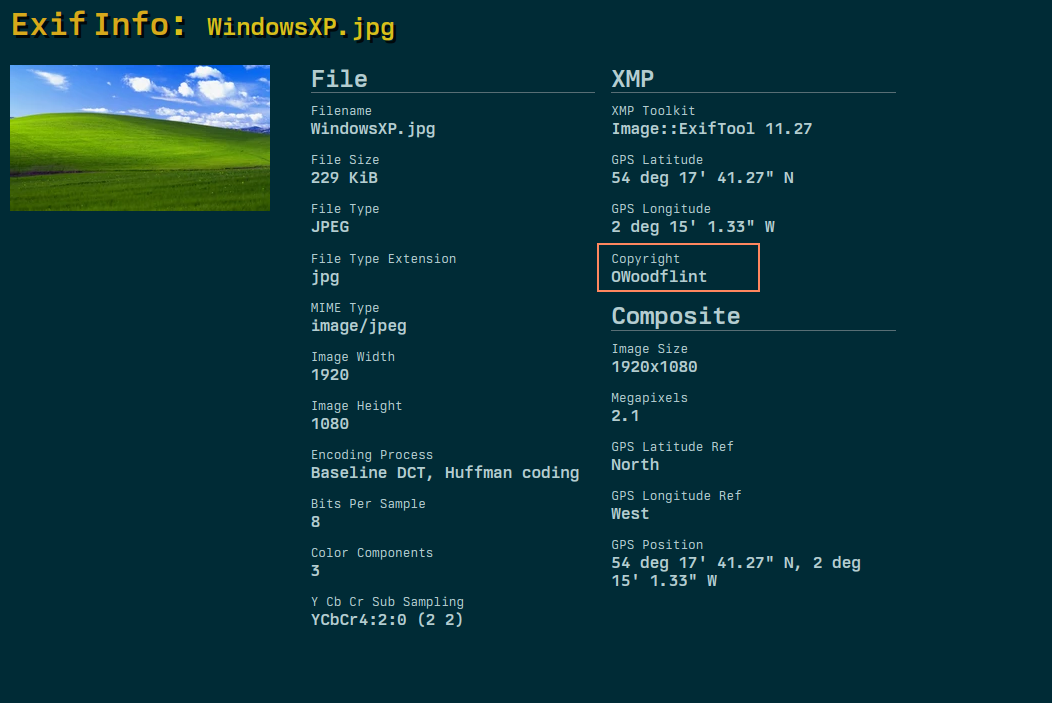
Inside of the copyright section we can see a name that is unfamiliar to us let's search it in google to get more information:
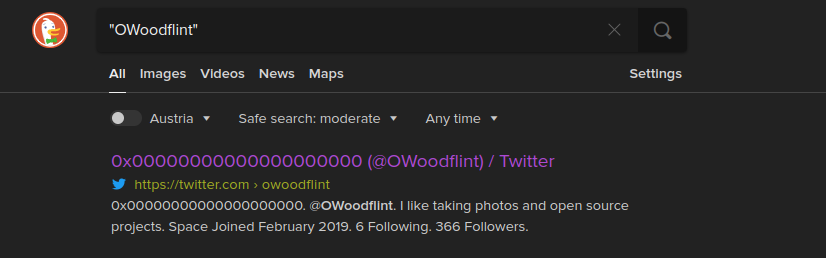
In this case we find a twitter account without needing to do more research. You can also see in the previous picture I used quotes around the word I am searching for that is a shorthand for using the intext search operator.
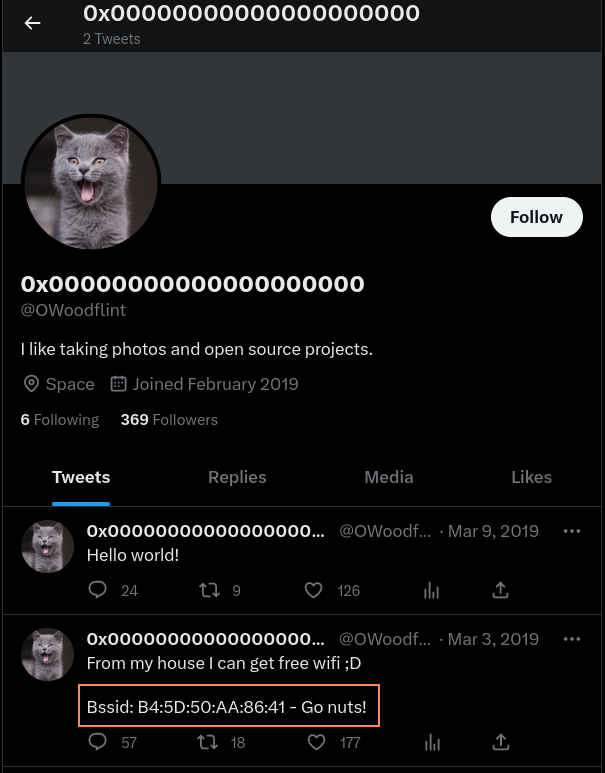
Inside of the twitter posts we have some other information we are not familiar with something called a BSSID. After some google we realise that the BSSID is a address that is assigned to a wifi. (more here) Now I will give a little hint from my technical background and experience but a BSSID is always matched with something called a SSID and that is the name of the wireless network for example 00:00:00:00:00 is the BSSID of Starbuck's Wifi the name is always matched with a number. There is a thing named WarDriving which is a group where people go around collecting wifi names and Id's and uploading them online on a map. The biggest one is operated by Wigle. So we can use their map to find where is located certain networks:
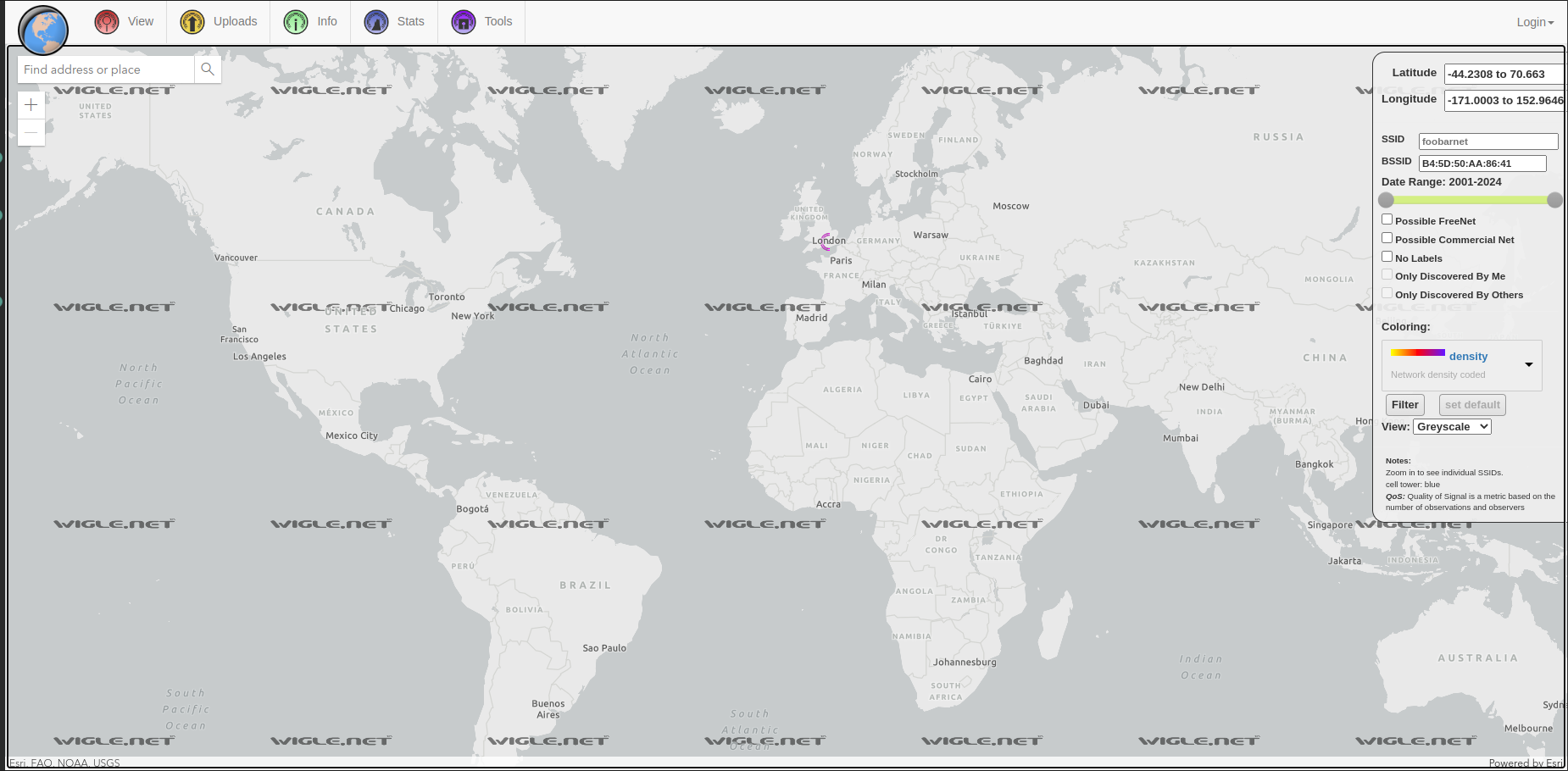
With the wigle search we can see a circle around the UK so this is most definitely where the person is located in london next to Regent Street:
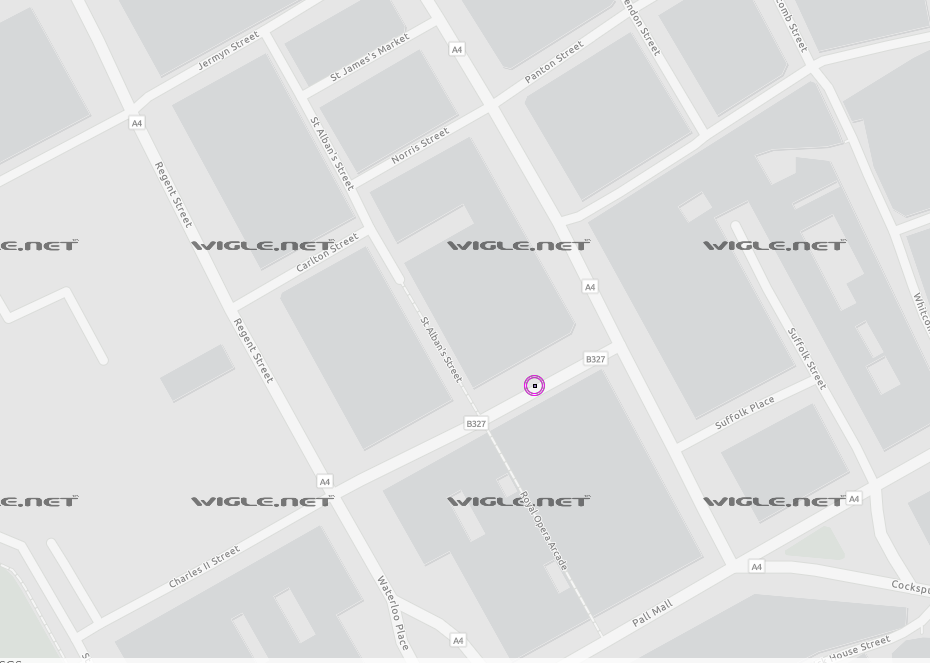
After finding this information we can get more information about the access point on wigle.net by creating an account.
After this rabbit hole we can now go back to our search and see what else we can find. To change we can search on google to see what can be found there for a change:
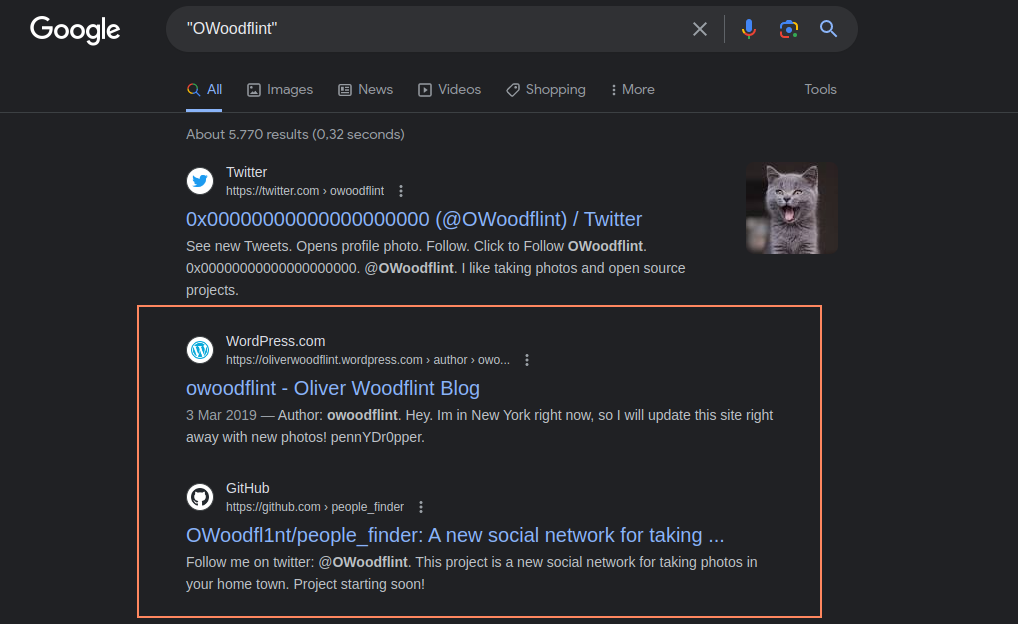
This is a different set of result for us where we find a blog tied to the username and a github account. Going through the mentioned blog we can see that he has posted information about his up coming holiday:
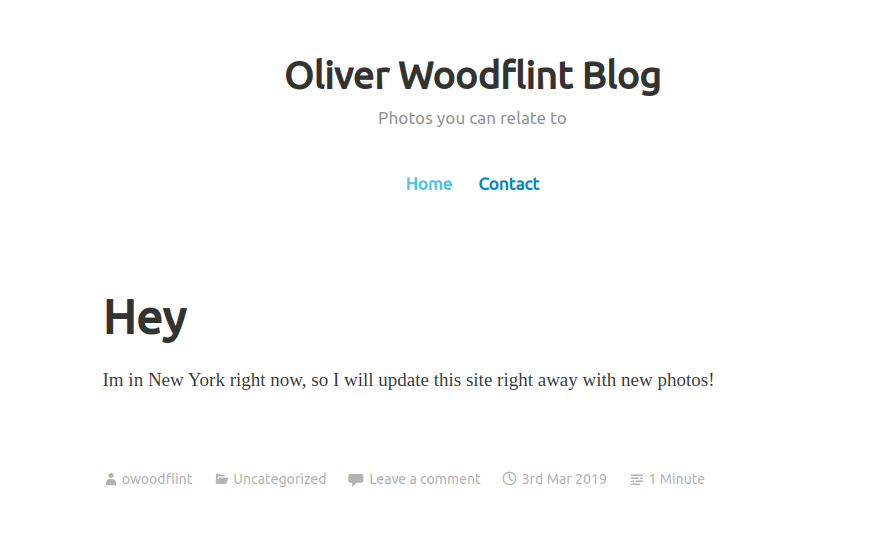
Inside of his blog post we can see that there is his full name which can be used for later on out research. We can also start inspecting the github account of the Oliver by looking at his only project which is people_finder.
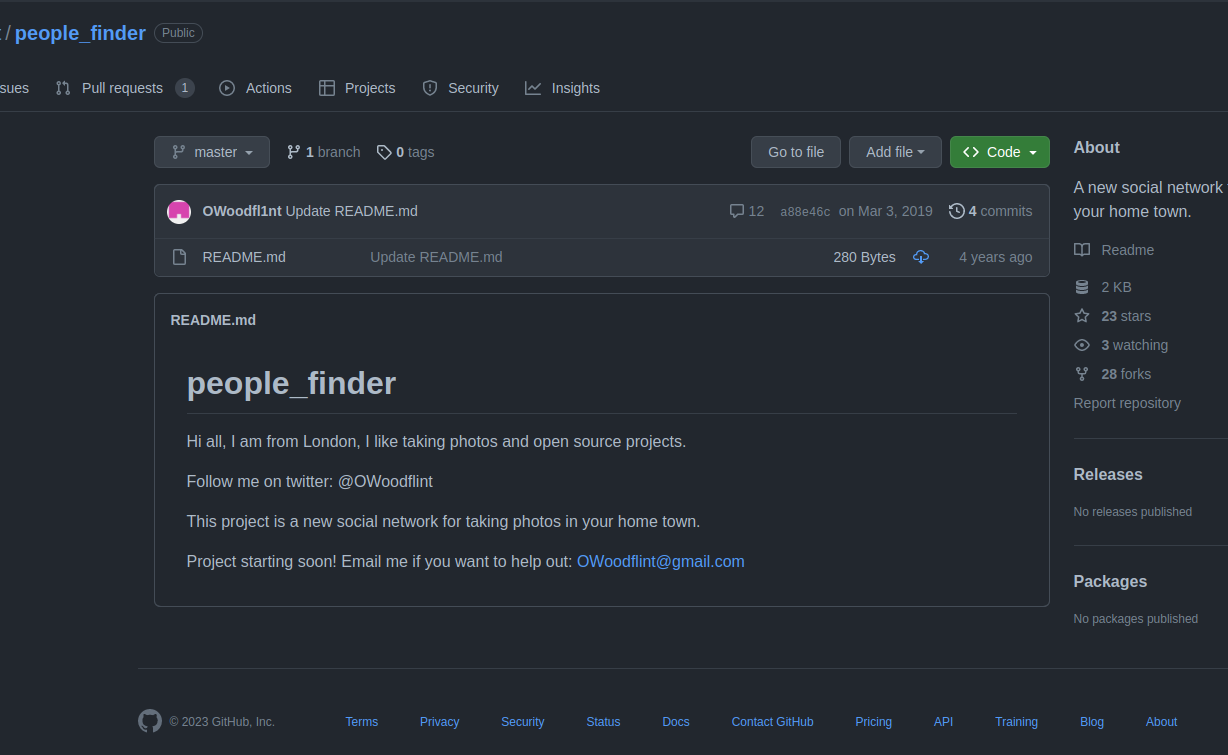
Here little oliver did kindly give us his email address that we can then look online to enumerate him further. The cool thing with github is we can go back in time without needing external help like the wayback machine. We can just got through something called a commit history. On github this is used to view the changes done to a project and see who changed what.
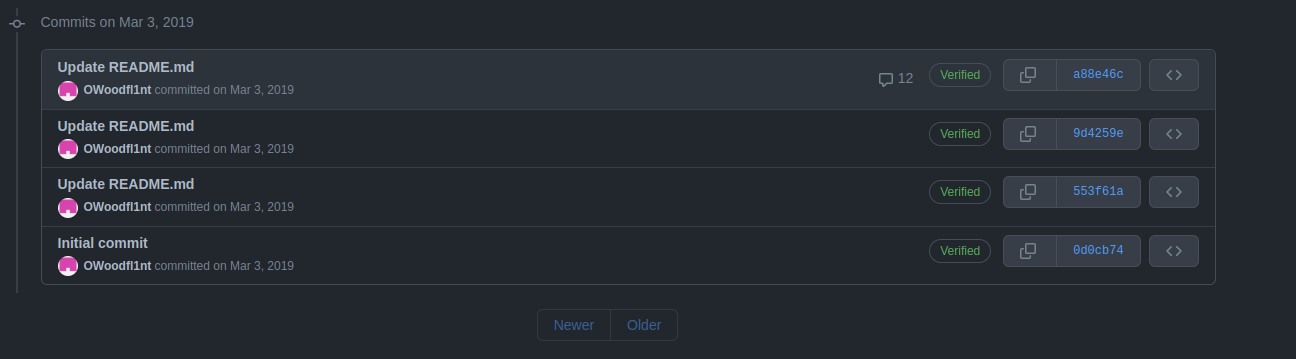
We can see that there has been 4 edits to this repository specifically so we now need to go through them one by one. All of this little tutorial is a quick introduction to what OSINT looks like there is a lot more to cover but to keep this post straight to the point I'll stop here.
Conclusion
Now from here I would recommend trying it out a bit more there are some online challenges that do exist to give an idea of what OSINT's like. There also is a certificate offered by TCM security that I highly recommend even if you are just learning this for fun that certificate is worth every penny and is brilliant to get started it is quite often on sale as well. There is also a non profit that does organise CTF's and events to get practice on OSINT with a nice discord group to meet people who are into OSINT as well (here).
I hope reading this blog post taught you something new and you got to discover an interesting new field. I think OSINT is not just a cool thing but a really useful skill to then be able to learn other things. I personally use it for so many things from job search, learning new skills (OSINT is brilliant for findings books on a certain topics without forking out the cash). Please do consider my other blog posts if you are new they are quite technical but I always try to explain my work as simple as possible. I might be doing more posts like this in a more educational way in the future instead of just either showcasing my work or explaining how I completed certain exercises. Also my github has cool projects you can check out if you are interested in proper technical content.
Book a phishing campaign
You can book a phishing campaign from me on your organisation by contacting me.
LinkedIn or twitter / X. I also use twitter as a platform to update on new posts!Questions / Feedback
Donate
If you like the content of my website you can help me out by donating through my github sponsors page.